 Articles
ArticlesParselets: Parsing and modifying code
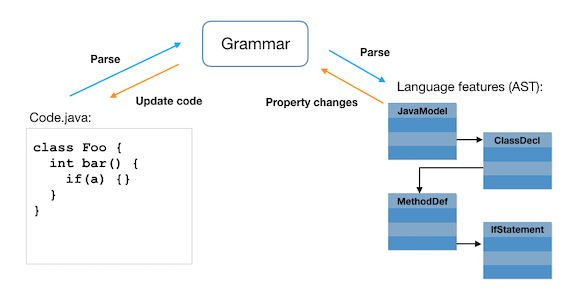
Parselets is a Java library for building parsers using a Java API to define parsing expression grammars (PEG). Annotations added to these grammar elements assemble the abstract syntax tree, the API for classes, statements, variables or other parsed things. With Parselets, this API also supports changes to the model that update the source code. Localized changes in the model are localized in the code, preserving surrounding comments and formatting not stored in the AST.
The main benefit of Parselets over other parsers is how quick it is to develop new grammars and complete APIs for manipulating the contents of a given file format. With more annotations, grammars support great partial matches suitable for IDE editing, syntax highlighting, error detection and more. It's possible to build a complete IDE plugin for a new format with much less code than separately writing the lexer, parser, AST builder, and formatter separately.
Like most PEG grammars, parselets are easily composed, extended, modified, etc.
The Java to Javascript converter transforms a Java AST into a JS AST using shared parselets and base-classes. To convert a Java array to a JS array, just change the language and reformat.
PEG parsers are composed of four basic types of matchers: a Symbol, SymbolChoice, Sequence, or OrderedChoice. There are parselet classes for each of these types and also IndexedChoice for a faster matching that's useful in some cases. Some language constructs are created directly from these primitives, others use subclasses like KeywordSpace inherited from a BaseLanguage. A Sequence parselet can specify an AST class to be created when that node is matched. The parts of the sequence map populate properties of that class. There's a descriptor string associated with the parselet that contains this mapping that looks like: "className(mapping1,mapping2)". Where the mapping strings can be empty to skip the value, the name of a property, * to inherit child mapping, or . to pass through the matched value. When className is not provided, the mapping can be '' for any slots that are included as part of the string semantic value. The value [] can be used to add that slot to an accumulated array value.
Example grammars
StrataCode is built on Parselets including a base language for shared parselets like whitespace. There's a simple pattern language used for bi-directional parameters in URLs. There's a Java language grammar, SC language grammar, SC template language, schtml, javascript, xml, and a sql ddl for Postgres.
Many of these formats can be used from the IntelliJ plugin that's built on parselets.
Performance
Parselet grammars are not as fast as table-driven parsers but do use indexed choice primitives where possible. Caching can be enabled for those grammar nodes that are shared by more than one choice. For the sc formats performance is pretty good without having done extensive performance tuning.
AST's and the layout of the parse-node tree can be serialized separately and either or both restored to speed up the parsing operation on files that have not changed.
Parse-node trees also take up more memory for the information used to do the incremental generation. There are a few optimizations still to be made to easily reduce the amount of memory these parse-node trees take up, and they only need to really be in memory for the process of parsing a file initially and later transforming one incrementally.
Learn more
See the simpleParser example for a standalone program that processes Java source files in a java source path/class path.
Details available in the doc.
 StrataCode
© 2020 Jeffrey Vroom
StrataCode
© 2020 Jeffrey Vroom