 Documentation
DocumentationStrataCode's parsing, AST modelling, transpilation and code generation framework
Parselets supports development of code that needs to read and write code in different formats. It supports code analysis tools, code-preprocessors (like StrataCode), code editing and IDE features, and transpilers that convert one format to another.
With parselets, grammars are built from Java code using a declarative syntax to programmatically wire together parselets. Parselets can be extended, overridden, copied, modified, etc. There's no generated code for the parsing phase so it's possible to override behavior with a sub-class. To make parsing fast, use efficient grammars, enable caching, and use an IndexedChoice.
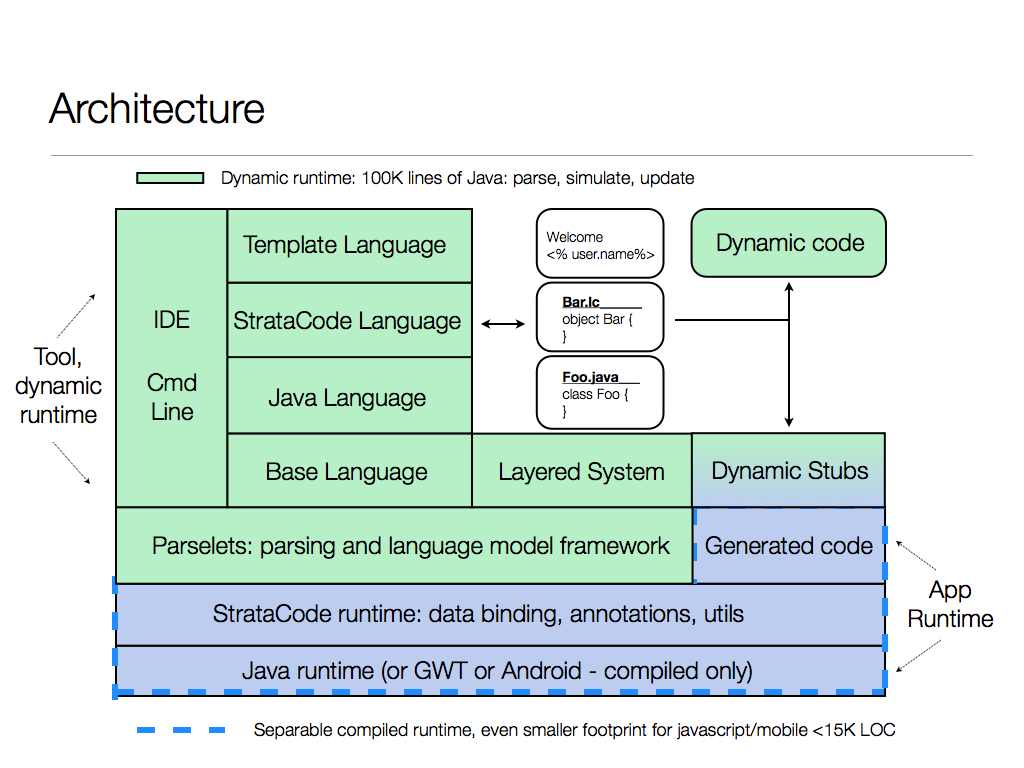
Here's an image of the StrataCode architecture showing parselets and the languages that use it.
Parselets are built using a type of recursive descent grammar, known as a "parsing expression grammar" or PEG. In addition to the PEG grammar used for parsing, provide class and slot mappings to build the AST. These objects can be high level types like ClassDeclaration, IdentifierExpression. The grammar imposes some limitations on the interface of these types, but altogether the result is very usable and readable and it's easy to trace how a property is produced from the underlying language, or vice versa.
The grammar to model mapping becomes a guide to understanding the model, a validator to validate the model, and a bi-directional mapping to the code all-in-one.
Parselets maintains two main data structures which are interlinked in a parallel way: the parse-node tree and the semantic model tree. The parse-tree represents mapping from text regions in the code to matched entities in the grammar. The semantic model tree is the AST - the model generated from the grammar.
The mapping between the two is maintained automatically, even as the semantic model is changed. For example, as you change properties in the model, the parse-node tree is updated to reflect the changes. These changes enforce the rules of the grammar - if the changes make an invalid language model, you get an error that helps you trace down the model problems.
As you define the model mappings to your grammar, care must be taken to preserve enough information in the model for bi-directional transformations. If your grammar does not generate a model which preserves enough information, it can still be parsed but cannot be re-formatted using the same grammar.
Spacing and other elements which are not included in the code model still can be formatted as code by inserting behavioral parse-nodes that can be expanded on another pass when all of the context to do is available.
In some cases, the AST generated by StrataCode is not a complete model of the underlying language. In these cases custom logic must be written to add the additional information.
For example, expressions are parsed initially into a linear list, which is converted into a tree with the proper precedance rules.
Organizing StrataCode parselets
Parselets are grouped together and maintained in a subclass of the abstract class Language. This base class groups the parselets into a name space that makes it easy to find and debug parselets. All parselets must be assigned to a field in the Language. The field names are used as the default names for the parselets.
When one Language class extends another one, it gets its own copy of all of the parent language's parselets. But because the field names keep the correspondence between the two languages, we can more easily convert one language to another using common base languages to maintain the common names of constrcts that need converting.
Each language defines a graph of parselets which implement the language. There is usually a start parselet defined on the language or a language can expose certain "public" parselets so you can parse subsets of the language.
Because we use Java's field initialization semantics, when you have cycles in the graph of parselets (which is common), you must define a parent parselet before you set it's child nodes in some cases to break these initialization cycles. None of the parselets are initialized until the language itself is initialized so it's safe to modify parselets during the Language class initialization.
Parser algorithm
Each parselet can either accept or reject the input string by matching against. If it accepts the string, it also produces a semantic result. Nested parselets match child parselets to see if they match.
The StrataCode grammar is based on just a few simple core parselet base-classes that do the heavy lifting of both parsing and code formatting:
- Symbol: matches a single character or consecutive sequence of characters
- SymbolChoice: matches one of a set of characters or sequences of characters
- Sequence: matches a list of other rules chained together
- OrderedChoice: takes a list of other language elements and tries to match them in a
- IndexedChoice: a more efficient way to implement a choice where a prefix string unambiguously selects a potential match. If there is no indexed match, an ordered choice of parselets can be used as a fallback.
Each parselet provides an "accept" method which you override to reject the string parsed by that framework. This provides an easy way to customize the matching logic using Java code.
You can set various flags on each parselet to customize how that parselets matches its input text:
- OPTIONAL - if there is no match, produce an empty result rather than an error
- REPEAT - look for more than one match of the input string
- NOT - only match if the default parselet rule does not match
- LOOKAHEAD - attempt to match but do not consume the matching input string. In this case, the matching string is not used as the semantic value for the node. In other words, the semantic value is null always.
- NOERROR - if lack of a match should suppress the generation of an error.
One technical limitation of the recursive descent algorithm is that it cannot handle "left recursive" definitions - in other words, when you have a sequence, the first node in that sequence cannot be a reference back to the node itself. Or in other words, the first node in the sequence must match and consume some text before it tries to match a recursive definition.
Defining Semantic Values
In the parsing world, matching is just the first step in the process. Once you have matched the input text, and broken it into chunks which represent each semantic element, you need to build a model of the resulting language structure. This is called the semantic model or semantic value of the parsed result. Each parselet definition optionally specifies a string value which can specify a Java class to create to hold the semantic value of that node. If it specifies a name in angle-brackets, that is a name used for debugging and specifies that the parselet has no class. Primitive parselets like symbols or symbol choice will use their string value as the semantic value.
There are a variety of mapping types for semantic values.
No name
For example, this defines a parselet using the low-level Symbol parselet that matches the semicolon:
Symbol semicolon = new Symbol(";");
This parselet is an anonymous parselet: no name or mapping for a semantic value is provided. When there is no mapping, the semantic value is null. Even a node with a null semantic value can be turned into a string by its parent though. In that case, the matched string becomes the string value of the node.
Semantic class with simple property mapping
The syntax of the parameter mapping string is:
ClassName(prop1, prop2)
This creates an instance of class "ClassName" and assigns prop1 to the first slot, prop2 to the second slot.
For example:
Sequence normalClassDeclaration = new Sequence("ClassDeclaration(operator,,typeName,typeParameters,extendsType,implementsTypes,body)", classOperators, spacing, identifierSp, optTypeParameters, extendsType, implementsTypes, classBody);
This grammar snippet, defines a sequence which upon match creates a new instance of the Java class called ClassDeclaration by assembling pieces from other parselets. The "operator" property of ClassDeclaration comes from the semanticValue of the classOperators parselet. The spacing in the second slot is ignored with the missing slot name in "operator,,typeName". The typeName comes from the identifierSp parselet. The semantic value of that node is the identifier as a String without the trailing space. Next the typeParameters property is filled optionally with optTypeParameters and similarly for the rest of the properties. The final property is a classBody which comes from that parselet. This is a SemanticNodeList
Each language specifies one or more packages called the "semantic value classpath". For the Java laanguage, this includes the package sc.lang.java.
Anonymous Name
<name>
A name in angle brackets gives a way to identify the parselet in the debug output without assigning a semantic class.
Propagate a child value:
(.,)
When you specify no name, you can still provide property mappings. The simplest form will use a "." character as the slot name in one slot. This propagates that slot value while omitting the semantic value of the other slots. This parselet uses the semantic value of the formalParameterDecls child parselet, ignoring the values of openParen and closeParen:
Sequence formalParameters = new Sequence("<parameters>(,.,)", openParen, formalParameterDecls, closeParen);
Collect properties from a child parselet
ClassName(prop1,*)
Creates an instance of class ClassName, sets prop1 to the first slot. Looks for additional property mappings from children in the second slot. That slot specifies a parselet either with another "*" construct, or a mapping like (prop2,prop3) which specifies additional properties to be set from parselets produced in the child. For example:
Sequence variableDeclaratorId = new Sequence("(variableName,arrayDimensions)", identifier, openCloseSqBrackets); Sequence variableDeclarator = new Sequence("VariableDefinition(*,*)", variableDeclaratorId, new Sequence("(operator,initializer)", OPTIONAL, variableInitializerOperators, variableInitializer));
This parselet defines a VariableDefinition from two slots. The first slot is a variableDeclaratorId which sets the variableName and optional arrayDimensions properties. The second slot is set by a third sequence which contains the optional equals operator and initializers. All four of those properties end up populating the same instance of VariableDefinition when a successful match is made.
Set Properties on Child
(propName1,.)
Inherits the value from one slot and sets properties on it before passing it up the chain.
Sequence forStatement = new Sequence("(,,.,,statement)", new KeywordSpace("for"), openParen, forControl, closeParen, statement);
Propagates the object created by forControl and sets "statement" on that object. The forControl parselet is a choice of each of java's for-loop syntaxes. The parameter mapping for the forStatement sets the "statement" property from the statement following the closeParen.
String Value From Children
('',,'')
Creates a string value from each child slot with the '', concatenating them in order. The result is a longer string which omits the string values of any skipped slots.
Sequence openCloseSqBrackets = new Sequence("('','')", OPTIONAL | REPEAT, openSqBracket, closeSqBracket);
The openCloseSqBrackets parselet concatenates the values of the openSqBrackets. You might think this should be the default, but because most parselets have to deal with parsing it is quite common for even simple parslets like "openSqBracket" are sequences where the semantic value has stripped off the space from the parsed value.
Array Value From Children
This pattern lets you build a single array value from the matched language elements:
([],,[])
It works like string slot names (e.g. "('','')"), but instead of concatenating strings, it takes the values of the first and third nodes and adds them a List (of type java.util.List or SemanticNodeList) it returns as its semantic value when the node completes its match. Note that this List's element type will be the super-type of the first and third slots in that sequence. If the first is a String and the third is a ClassDeclaration, the result would be a List of type Object in the model.
The semantic value for the parselets in the Array slots may either be arrays themselves, java.util.List objects or scalars. The parser never produces multi-dimensional arrays so all array elements are merged into a single list. The order is always defined by the order of the objects in the parsed file.
Here's an example from the JavaLanguage which matches the Java modifiers that precede a field, method, or class:
OrderedChoice modifiers = new OrderedChoice("([],[])", REPEAT | OPTIONAL, modifierKeywords, annotation);
The semantic value of modifiers combines each of the semantic values of all children nodes, in this case modifier keywords and annotations. They are all returned in a single list in the order in which they were present in the original file. The keywords are returned as Strings, the annnotation as an Annotation object so the type ends up being SemanticNodeList<Object>.
Special case: Propagate child, create new child if null
ClassName(prop1,.)
Propagate the value in the second slot and set the "prop1" property on that instance to the value of the first slot. If the second slot is null, create an instance of ClassName and set prop1 on that. For cases where there is potentially a more detailed instance created in the second slot this can be a useful way to deal with some conditionality in the model.
OrderedChoice identifierSuffix = new OrderedChoice(OPTIONAL, new Sequence("ArrayElementExpression(arrayDimensions)", new Sequence("(,[],)", REPEAT, openSqBracket, expression, closeSqBracket)), new Sequence("IdentifierExpression(arguments)", arguments), new Sequence("TypedMethodExpression(,typeArguments,typedIdentifier,arguments)", periodSpace, simpleTypeArguments, identifier, arguments), new Sequence("(,,.)", periodSpace, newKeyword, innerCreator)); // varIdentifier includes "this" and "super" // Note on this definition - we define a result class here and also propagate one. If identifierSuffix returns // null we'll use the result class on this parent node and create a default IdentifierExpression. If not, we // just set the identifiers property on the identifierSuffix object. Sequence identifierExpression = new Sequence("IdentifierExpression(identifiers, .)", new Sequence("([],[])", varIdentifier, new Sequence("(,[])", REPEAT | OPTIONAL, periodSpace, identifier)), identifierSuffix);
In this case, there are two main parselets defined: identifierSuffix determines what follows the "a.b" part of an identifier expression. That gets created if you have method arguments, an array element expression or a couple of other special cases not used commonly. If none of those are present, the grammar sets the identifiers property on a brand new IdentifierExpression instance created. If the second slot returns a non-null value, that is the IdentifierExpression instance whose identifiers property is set.
ChainResultSequence
ChainedResultSequence parses just like a regular sequence - the only change in behavior is how the semantic value is produced once the sequence matches. This sequence always has two slots. If the second slot is null, the value of the first slot is used. If the second slot is not null, the normal sequence processing rules are performed to determine the sequences value.
Typically it is used in conjunction with a propagate rule which propagates the second slot and sets the first slot as a property on that slot.
So this node's produced type is the common superclass of the first slot or the second slot. Because there is conditional behavior though in how the parser uses the slot mappings, it can't define the slot mappings on that type. Instead, it chooses the slot mappings based on the propagated value's type (if any) which will usually be the first slot.
Spacing
Because lexing and parsing are in a single pass, you need to consider spacing as part of your grammar. Usually low level constructs such as identifiers and symbols include spacing after the symbol so this is isolated to a few low-level constructs. When your semantic model does not include spacing, you can implement smart formatting by injecting your own sub-class of parse node. See NewlineParseNode and SpacingParseNode. These classes are put in to the output during the generate phase. After the generate phase is complete, the parse tree may be formatted to produce a string value. At this time, the smart parse nodes using information in the FormatContext object to make a good decision as to whether or not to include spacing, indentation, newlines etc.
Parselets have flags to turn on/off spacing so it is easy to control whether spacing is injected into a formatted representation or not.
Utility Parselets
See BaseLanguage's inner types: SymbolSpace, KeywordSpace, KeywordChoice, SemanticToken, SemanticTokenChoice for easy building blocks for robust behavior. SymboSpace treats the symbol as the semantic value and matches any trailing white space. KeywordSpace is like SymbolSpace but also ensures a non-identifier is the next character (avoiding "newClass" from matching the "new" keyword). KeywordChoice takes a list of keywords as possible matches. A SemanticToken is like a SymbolSpace during parsing. During generation however, a SemanticToken requires a non-null value to match. It should be used for things like the "extends" keyword which adds additional functionality when paired with a non-null value.
IndexedChoice
Indexed choice is a more efficient way to parse a long set of choices when there is some prefix string that must be present for a given match to be considered. Any choices that do not have a known prefix are put into the default list for the choice. Those are evaluated on any potential match. A good example of an IndexedChoice is the Java "statement" parselet:
public IndexedChoice statement = new IndexedChoice("<statement>(.,.,.,.,.,.,.,.,.,.,.,.,.,,.,.)"); { // Add a set of indexed rules. We peek ahead and see if any tokens // match and redirect the parser to the appropriate statement if so. statement.put("{", block); statement.put("if", ifStatement); statement.put("for", forStatement); statement.put("while", new Sequence("WhileStatement(operator, expression, statement)", new KeywordSpace("while"), parenExpression, statement)); statement.put("do", doStatement); // Note: this does not enforce the try must have one catch or finally rule. statement.put("try", new Sequence("TryStatement(,statements,*)", new KeywordSpace("try"), block, new Sequence("(catchStatements,finallyStatement)", new Sequence("([])", OPTIONAL | REPEAT, new Sequence("CatchStatement(,parameters,statements)", new KeywordSpace("catch"), formalParameters, block)), new Sequence("FinallyStatement(,statements)", OPTIONAL, new KeywordSpace("finally"), block)))); statement.put("switch", new Sequence("SwitchStatement(,expression,,statements,)", new KeywordSpace("switch"), parenExpression, openBraceEOL, switchBlockStatementGroups, closeBraceEOL)); statement.put("synchronized", new Sequence("SynchronizedStatement(,expression,statement)", new KeywordSpace("synchronized"), parenExpression, block)); statement.put("return", new Sequence("ReturnStatement(operator,expression,)", new KeywordSpace("return"), optExpression, semicolonEOL)); statement.put("throw", new Sequence("ThrowStatement(operator,expression,)", new KeywordSpace("throw"), expression, semicolonEOL)); statement.put("break", new Sequence("BreakContinueStatement(operator,labelName,)", new KeywordSpace("break"), optIdentifier, semicolonEOL)); statement.put("continue", new Sequence("BreakContinueStatement(operator,labelName,)", new KeywordSpace("continue"), optIdentifier, semicolonEOL)); statement.put("assert", new Sequence("AssertStatement(,expression,otherExpression,)", new KeywordSpace("assert"), expression, new Sequence("(,.)", OPTIONAL, colon, expression), semicolonEOL)); statement.put(";", semicolonEOL); // Default rules in case the indexed ones do not match statement.addDefault(new Sequence("(.,)", expression, semicolonEOL), new Sequence("LabelStatement(labelName,,statement)", identifier, colonEOL, statement)); }
To form a valid IndexedChoice, you register each indexed parselet with its key prefix. Those parselets are only tested when the input string matches the string registered for the key. Any parslets that do not have a unique prefix string are included with the addDefault method and tested each time.
Keywords
The BaseLanguage class defines Keyword subclasses of Sequence to help you add keyword semantics to your grammar easily.
The only challenge for keywords is to ensure that any following text is not part of an identifier - i.e. to differentiate between "new Foo()" and "newFoo = 1". We do that with a NOT | LOOKAHEAD rule which rejects any identifier chars following a keyword.
During generation, keywords are usually straightforward. They are in general used to select a model class and so may be indirectly represented in the semantic model. We select the matching "choice" option using the class of the model. At that point, the keyword parselet must just ensure the keyword is generated in the spot in which it was parsed.
Operators
Operators are usually just set as properties in the model. The model can validate the operator and map that to an enum if necessary. We can just use that operator property then to format the property character in the model.
Newlines
Newlines are a special type of spacing (see above). During the formatting process, a NewlineParseNode is generated. During the format phase, the NewlineParseNode looks at its context and determines both whether a newline should be inserted and how much indentation should be added after the newline. It can look at the the semantic values before/after it in the parse tree. It can look at the suppressNewline flag put into the context by the parent parselet. Using these techniques, the formatting is kept to just a few tweaks to the grammar.
SemanticTokens
In some cases, a token can add additional information to the semantic model which implies an additional construct is present. For example, the 'extends' operator implies an additional type is present. For these constructs, use the semantic token. It rejects a formatting match if the semantic value is null. For example, the extendsType property is null implies that we do not generate an "extends Type". Since that sequence is optional in the model, it just aborts that chunk of the formatting process.
If during generation operators or keywords appear when there is an empty construct, that's the place to use a SemanticToken. It will suppress the keyword unless there is a non-null value.
Considerations for Generation
The model must preserve enough information from the original result to re-generate a result. When you reach a choice node, it will match the input against each choice. First the type of the object is matched as that can select the proper choice quickly and unambiguously. Then StrataCode tries to generate each choice - if the choice produces an error, that is thrown out. If the choice matches, that is stored as the current result. If another choice matches, the OrderedChoice class picks the longest result - i.e. the one that has the most information or is the most specific match. In general, the rules enforced by generation seem to help clean up the grammar making it easy to build read/write models.
Considerations for the model/semantic value mapping
By default, a node has no semantic value. You need to specify some parameter mapping string at some point for each value to assign it as a value, a string, a class of its own, or a List of some type. Each parselet therefore has some type. If no semantic value has been defined for it or its children, its type is undefined - its semantic value result will always be null. This can be fine for non-semantic elements in your language such as comments (though of course comments may well be semantic depending on your intentions with the language model).
Each parselet with a semantic value will have a type.
As you define a mapping for your parselets, the types must match for it to be valid. This catches flaws in your model to language mapping in general when the grammar is validated. For an OrderedChoice, the type is the common-super class for all of the semantic values of its children.
If you need both code parsing and code formatting (aka code generation) in your model, use the sc.parser.SemanticNodeList class for any multi-valued properties in your model. Make sure to specify generic types since these are enforced by the grammar as well - e.g. SemanticNodeList<Object> or SemanticNodeList<Statement>.
Type conversions are performed in the following circumstances:
- a single value object can be assigned to a SemanticNodeList
property as long as the type matches. - a parse node or other type can be assigned to a String property using a toString method.
- any non-null value, usually a flag-type keyword in the grammar can be assigned to a boolean slot in the semantic value class. This is a nice way to capture a true/false state in the grammar. During parse time, if this value is omitted the parsed value is null and the value is set to false. During generation time, if the value is false, the parser converts that back to a null value and does not generate the construct.
- The TypeUtil class provides support for adding additional automatic conversion types. Keep in mind when adding a new converter that you have to both implement the setProperty so that the semantic-value coming from the parser gets converted to the type expected by the Bean and you need to convert the parsed value back to what the parser expects for generation.
Generating Empty Lists
One problem with generation is when you have a construct with an empty list. That value may be treated as an "empty value" - i.e. we match an optional parselet and return null for the generated parselet. For other parselets, you need to treat it as a non-null value - a list of length 0. For example, if you have a sequence of '(', list-of-things, ')' that sequence needs to treat an empty list as a value so it gets to generate the open and close parens. The "list-of-things" parselet though should ignore that value - it is probably marked as "optional" and so should match and return null in that case. This is implemented via a property on the Parselet object: "ignoreEmptyList". The default is "true". If you find that you are missing the () in the generated output though, find that sequence with the '(' and mark it with ignoreEmptyList=true.
The SKIP flag
When generating the parse-tree for simple models, it is useful to omit an intermediate parse node in the result. The children of one sequence are added directly as children of that node's parent. You can set the skip flag and intermediate nodes are not generated. This optimization is disabled however when you assign parameter mappings - we need those intermediate parse nodes to assign the mappings.
Tracking Changes
The SemanticNode has a "setProperty" method which you can use to modify a model. The system automatically figures out which parse nodes need to be re-generated and re-generates them the next time the model is saved. The SemanticNodeList class similarly overrides the add, remove etc. methods so you can make arbitrary changes to a model and still save it (as long as it still matches the grammar). As much as possible the incremental changes are done incrementally so we preserve non-semantic elements in the untouched regions of the model. How much this is possible depends on how structured the semantic value to language representation is. If you turn the language into one large string, we'll regenerate that entire string. If you parse it up into properties and values of strongly typed objects, it allows you to incrementally change names, insert new constructs etc. without losing any of the original parsed representation.
Comments In or Out of the Semantic Model?
Comments can typically appear anywhere in the semantic model and so it can be a lot of work to maintain them in an ordered way in the model. Every identifier or operator might need to store a list of comments. This is cumbersome and expensive from a memory perspective.
Instead, you can just omit them from the semantic value. Because this system lets you keep the original parse tree, and the original parse-tree is tied to the model, you do not need to preserve comments, spacing etc. in the semantic model to be able to edit the model. This is memory consumptive but if you are not editing the model, you can throw away the parse tree. This makes this approach pretty flexible. From one code base, you have an efficient front-end to a compiler and a language model. This is all driven from a single representation.
Debugging Grammars
There are debug flags you can turn on though the volume of output they produce is quite large even for relatively small grammars. These debug print statements will log before/after statements for each attempted match in the grammar for both the parse and generation phases.
Probably the best way though to debug a grammar is to use the TRACE flag. You can set this on a particular node and it will enable selective debugging of just the sequences involvin that node or a child of that node. This still can produce too much output and probably the easiest way to debug a particular problem is to set a breakpoint at the code when the traced node is encountered. The primitive nodes Sequence, OrderedChoice have statements at the top of the "generate" and "parse" methods which let you stop on a traced node. From there, you can step through the implementation of these nodes to see why it is not matching or perhaps matching something it should not match.
One note: make sure you are working with the parselets from the right language. Each StrataCode language extends a previous language, creating a complete copy of all of the parselets. So if you set TRACE on the JavaLanguage, it will be inherited from SCLanguage but not vice versa. If you are working interactively in the debugger, it can be helpful to set trace dynamically by evaluating an expression in the debugger:
sc.lang.JavaLanguage.getJavaLanguage().stringLiteral.trace = true;
Make sure you have the parser source in your debugger. Stop in the Sequence or OrderedChoice's parse or generate methods. There's code in there already to print a message if trace is enabled so you can stop there. Or it is very efficient to insert a bit of code to stop when the current input matches a given string. You can avoid a lot of time spent isolating a test by this diagnostic code you add just to debug a particular problem. The parser is a parameter to that method and its "toString" method shows you the next few characters in the input stream.
To debug the generation process, turn on GenerateContext's debugErrors. Without that mode, the errors generated are not specific. With that mode, parselets tracks the most specific generation error so you get a better idea of what part of your model is not matching the grammar.
How is it implemented?
This section is not primarily intended for users of the parser, but helps explain how it is implemented. There is also more detail that might help users understand the system one level deeper.
Parsing phase
During the parse phase, a parselet matches itself against the current input. If it matches, it returns a ParseResult, String, or implementation of the IString interface. If it does not match, it returns a ParseError.
The Language object is used to initiate a parse operation. Each language defines a global start operation or may expose one or more parselets to allow a subset of its grammar to be parsed. You can call the parse method on the Language object to initiate a parse. You are returned a ParseNode which has a SemanticValue. This is the Model object which corresponds to the parse tree. At any point you can detach the parse-tree from the model though it is best to leave them attached until you know you are not going to have to save the model. In other words, detach when you think the model is read-only. That way you preserve as much of the original formatting as possible.
During the parse method, the parselets build two parallel trees - the parse-tree and the semantic-vlaue tree. There are bi-directional links between these two trees. Each semantic value points to the highest node in the parse tree which was used in its generation. The parse node points to its semantic value (or null if no semantic value has been determined).
During the parsing phase, initially there is no semantic value defined. Each parselet can specify whther it wants to create a new instance of a particular class, generate a List of children either through a REPEAT node, use of [] or "array elements" in the parameter mapping, return a String value, or return null - no semantic value. So if no parselets specify any parameter mapping, the semantic value of the parsed result is null. If you are just testing the grammar or do not need to produce a model you can skip the semantic value stuff by omitting any parameter mapping info.
The parse method goes through a pretty circuitous route but this is for maximum flexibility in code-reuse, extension and enhancement. You start by calling parse on an instance of the Language you want to parse. You can optionally specify a parselet. This creates a Parser object to store state for the parse operation and calls its parse method. That method sets up state for parselet and calls its parse method. It will either the Parselet's parseResult or parseError method and return the result of that method. These methods deal with most of the optional behavior.
There are two main types of hierarchical parselets: the OrderedChoice and Sequence classes. The OrderedChoice takes a list of children and returns the first one which matches. The sequence requires that all of its children match (though of course some of those might be optional).
At the primitive level, there are Symbol and SymbolChoice. We add IndexedChoice by extending OrderedChoice and just making the choice of the matching parselets more efficient by matching a prefix string. Language constructs add higher level constructs such as Spacing, SemanticToken, out of these building blocks.
Generation and Formatting
The process of turning the semantic value into a string representation that can again be re-parsed takes two phases. First is the generation phase in which we generate parse-nodes from the semantic value. Once that is done, the formatting phase generates a string representation from the parse node tree.
For parsed nodes, the formatting phase just returns the parsed string values stored in the parsed tree.
During the generation phase, we build a generated parse tree. This is a slightly different type of parse tree than the one which is generated during the parse phase. In this tree we have not yet identified fixed characters to represent each parse node. Specifically we delay binding of spacing and newlines until the formatting phase. During the format phase, we traverse the parse tree and expand it into a string representation. During this phase, special types of parse nodes can look at the previous and following characters, the previous and following semantic values and customize the output based on the context. Though this process is a bit tricky, it makes for a very concise code base for all of this logic. See the SpacingParseNode and NewlineParseNode for examples.
An alternative way of implementing a grammar would be to just represent all of the text in the semantic value. In this way, you would essentially not need any special generated parse nodes to reproduce the string value. Both approaches are viable though by not representing comments etc. in the base language model, you can make use of that model significantly more efficient by representing low-level details by simple strings. This pays off in multiple ways throughout the development process.
Updating the Model
As you make changes to the model object using the SemanticNode.setProperty, SemanticNodeList.add, ... (remove etc. TBD), the corresponding parse nodes are invalidated and/or regenerated. The next time you need a string representation of either the model or you call parse=node.toString it will re-generate just the invalidated parts of the semantic model.
Key Data Structures
Parselet: the base parselet object. This defines the contract for the basic operations: parse, generate, format. It also defines the typing methods: getSemanticValueClass, getSemanticValueComponentClass (for Lists). There are setters used for propagating types around the tree as well in cases where a type is moved up or down the parselet graph.
NestedParselet adds support for child parselets. Sequence and OrderedChoice extend the NestedParselet.
IParseNode: this is the primary return value of a successful match. It is also produced by the generate phase - where a semantic model is turned back into a set of parse nodes. It has a "semanticValue" property which points to its current semantic value. It also has a parentParseNode property which points to its parent in the parse tree. A ParentParseNode is a subtype of parse node which stores a set of child parse nodes. This is produced by the NestedParselet subclasses: Sequence and OrderedChoice. When the SKIP flag is set on a parselet (the default) and that parselet is not used in any semantic mappings, the parser may skip generating a parse node for a given parselet. In this case, it may return the string which is matched in the input.
IString: an implementation of the String features which supports a way to represent the string value without copying characters from the input to the output. Primarily we use the StringToken classes internally which just point to a region of the input buffer. This avoids a lot of string copying during the parse phase.
ISemanticNode: this is the base interface for all non-string semantic values. Your model classes should extend the SemanticNode class if they need the model tracking functionality. Minimally they should implement this interface. Each semantic node has a pointer to the current parse node which it is was parsed from unless that parse-tree has been stripped off. You do that by setting the parse-node's semantic value to null - this detaches the two trees and allows either one of them to be GC'd if it is no longer referenced externally.
SemanticNodeList: a subclass of List which is used for representing collections of semantic values. Once a semantic value has been initialized and started (i.e. after it has either programmatically generated or parsed), it starts listening for changes and sends those events to the parselet from which this node is associated. That causes the parse-nodes to be regenerated to reflect the changes.
Context objects.
- For the parse operation, the Parser itself stores all of the intermediate context. A parser is created from a language with a Reader object.
- For the generate operation, a GenerateContext object is created. This keeps track of a set of masks which are used to filter out properties during the generation process. When we are generating linked lists for the generation to proceed properly we need to mask out certain properties so that the semantic model matches properly. These properties should appear as null to lower level parselets so that we can properly match the semantic value to the child nodes. A parent parselet will mask out properties in the GenerateContext, then invoke the lower-level node. When that node looks up property values in the semantic value, it first consults the mask and if it is set will just use null for that property. If no mask is set, the regular semantic value is used. We never modify the semantic value during this phase... the mask is stored in the GenerateContext.
- For the format operation, a FormatContext is created. This is used to track the stack of parse nodes which are currently being processed. For each parent parse node, we track the index of the child which is being processed. From a given parselet's format method, this means that we can walk that tree to figure out the given parse-node's context. What characters are before or after it in the stream and what semantic value is before/after it in the model. From that we can make good determinations about whether to include spaces or not.
The format context also keeps track of certain options to suppress spacing and to suppress newlines. This allows a parent parselet to modify the behavior of a given spacing parse node or newline parse node without creating a new definition of its children.
Parsing Efficiency
Though PEG parsers are not as efficient as LL(*) or LR grammars, the StrataCode parser optimizes search where possible using indexed choices nodes. For cases when reparsing is necessary, it's possible to cache intermediate results so that reparsing the same code the next time is about 3X faster.
Parsing Invalid Code
Parselets has very good error reporting for syntax errors. It also has support for generating partial models when your model does not strictly match the formal grammar. This is not only useful for building syntax highlighting and code completion in IDEs, but also for dealing gracefully with errors found in input files. There are additional properties: minContentSlot, skipOnErrorSlot, and skipOnErrorParselet to make error recovery easy to enable declaratively.
skipOnErrorParselet
Either a repeating OrderedChoice or a repeating Sequence can set the skipOnErrorParselet. The skipOnErrorParselet is used when a parent Sequence encounters an error parsing the next child after the child with the skipOnErrorParselet. In this case, the parseExtendedErrors method of the previous child is called to re-parse but using the skipOnErrorParselet to skip over errors. If it can skip over errors and match the exit parselet, a new extended match is returned. This list will return one or more matches of the skipOnErrorParselet. These results are represented by an ErrorParseNode containing the matched text.
This construct lets you easily terminate String literals that cross a newline or omit an invalid expression till the next semicolon.
So far, with these three constructs we've built acceptable IDE experiences for several languages, all using declarative grammars. It's easy to further tune the experience by further refining the grammars, not by writing tricky code dealing with token streams.
 StrataCode
© 2020 Jeffrey Vroom
StrataCode
© 2020 Jeffrey Vroom